「Python3入門ノート」例題のモデルで自分の手書き文字を分類する 〜データ作成から結果表示まで〜
こんにちは、食たまです。
私はPythonを「詳細!Python 3 入門ノート」(以下、テキスト)という本を使って勉強しました。

この本は、Python初心者のためのプログラミング学習教本ですが、最終章では機械学習を学ぶことができ、3つのモデル(学習をしてある入力から出力を導くもの)を作ります。
3つのモデルの内の1つが「手書き数字を分類する」モデルでしたので、このモデルを使って自分で書いた数字を分類してみました。
手書き数字の画像を作るところから、結果の表示まで全てスマホで完了できましたので、ここでご紹介したいと思います。
数字を書いて画像にする
先ずはここから。
手書き数字を書く
紙に書いたものを写真で取る方法と、手書きメモアプリを使う方法と2つやってみました。
紙に書いて写真で取る
普通に紙にサインペンで数字を書いて、スマホのカメラで撮影しました。

今回はクロッキー帳に書きましたが、地は白がおすすめです。クロッキー帳で書く前にピンクの付箋で試しましたが、白地の場合より分類の成功率が下がります。

手書きメモアプリを使う
手書きメモアプリには Google Keep を使いました。



Google Keep を立ち上げると右下に筆マーク  があるのでそれをタップ。
があるのでそれをタップ。
そこに、数字を書きます。

書けたら、右上の「3つ丸マーク」→「送信」→「ドライブに保存」を選択し、Google Drive に保存します。
1文字ずつ切り出す
画像データは学習に使ったものと同じ形式でなければいけません。
学習に使ったデータは、サイズが8✕8で、16階調のグレースケールでした。
なので、今書いた数字を8✕8サイズに切り出します。
そんな作業にとっておきのアプリを発見しました。その名も「写真リサイズ」。

これを使えば、切り出しとリサイズを同時にしてくれます。
アプリを立ち上げたら、さっき作った写真または手書きメモ画像を選択。

ここで、右上の共有マークの隣の四角が回ってるようなマークを選択。
すると、切り出し画面になります。
右上の「0x0」を押すと、サイズが選べるので、今回は「Custom」で8✕8と入力します。
正方形の明るい選択部分が現れました。
これを数字に合わせ左下の「Crop」を押せば切り出し&リサイズの完了です。

ルールに従って名前を付ける
保存するときに、画像に名前をつけるわけですが、この名前の付け方が重要です。
名前は、数字の分類後に答え合わせをするために、プログラムで答えを読み取れるようにすると便利です。
そのためのルールを作り、それに従って名前を付けます。
ルールは
- 正解の数字が含まれる
- 正解の数字以外は同じ文字列
- 正解の数字以外の文字列は数字を含まない(正解と混同しないようにするため)
今回は、食たまが書いた数字なので、「shokutama正解の数字.jpg」と名付けることにしました。
こうして、0〜9の10個の数字画像を作ることができました。
できたデータは Google Drive にフォルダを作って保存しておきましょう。
numbersというフォルダを作って保存しました。
画像データを取り込む
次に、画像をモデルに読み込ませるためのデータに変換する必要があります。
画像は Google Drive にあるので、Google Colaboratory から Google Drive のファイルを読めるようにしてから、画像をデータに変換します。
Google Drive のファイルを読めるようにする(Google Driveをマウントする)
これは、想像以上に簡単でした。というか、簡単になったようです。
調べてみると難しいことがいっぱい出てくるんですが、本当はたったの2行でした。しかも、自分で書く必要もありません。
Google Colab の左上にある「3本線」→「ツール」→「コマンドパレット」→「コードスニペットパレットを表示」と選択します。
(キーボードがあれば「Ctrl+Alt+p」でもOKです。)
こんな画面になります。
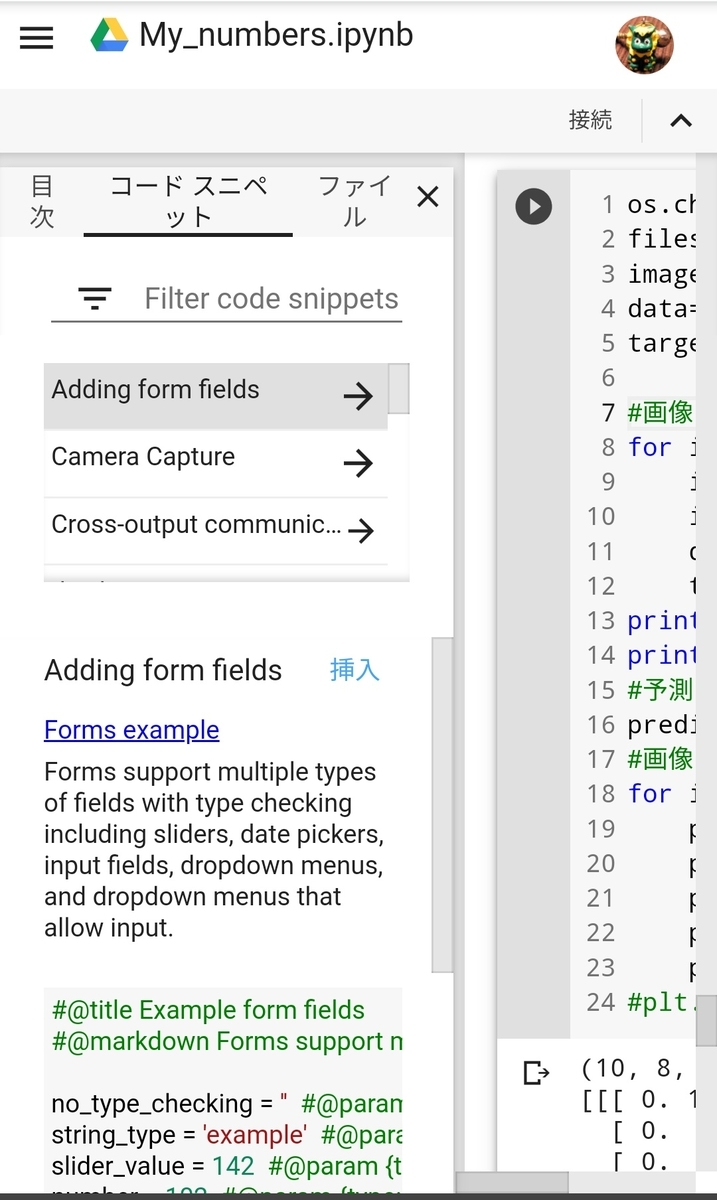
この「Filter code snippets」のところに「drive」と入力すると、
- Open files from Google Drive
- Mounting Google Drive
- Listing files in Google Drive
- ...
と候補が出てくるので、2番目の「Mounting」を選択。
そして、候補の下に出てきた「挿入」をタップすると、2つ新しいコードセルが現れ、そこには
from google.colab import drive drive.mount('/gdrive')
with open('/gdrive/My Drive/foo.txt', 'w') as f: f.write('Hello Google Drive!') !cat '/gdrive/My Drive/foo.txt'
と表示されています。
今回は1つ目だけでOK。2つ目は削除しましょう。
これを実行したときに現れるリンクへ飛び、自分のアカウントを選択、アクセスの許可をすると長々したコードが表示されるのでそれをコピーし、Google Colab に戻って貼り付け、Enter。

Mounted at /gdrive
と表示されれば連携完了です。
Google Drive にアクセスする
osモジュールを入れてファイルにアクセスしてみます。
import os #osモジュールをインポート os.chdir("/gdrive/My Drive/numbers/") #numbersフォルダへカレントディレクトリを移動 files=os.listdir() #numbersの中身リストをfilesに代入 print(files) #filesを表示させる
['shokutama7.jpg', 'shokutama2.jpg',
'shokutama8.jpg', 'shokutama1.jpg',
'shokutama0.jpg', 'shokutama9.jpg',
'shokutama3.jpg', 'shokutama4.jpg',
'shokutama6.jpg', 'shokutama5.jpg']
無事、さっき作った画像ファイルにアクセスすることができました。
画像データを読み込む
では早速、画像ファイルを分類器が読み込めるデータに変換していきます。
私は、cv2画像処理モジュールを使いました。
import cv2 #OpenCVをインポート image=cv2.imread("shokutama0.jpg",0) #shokutama0.jpgをグレースケールの画像データにしてimageに代入 print(image.shape,"\n",image) #imageの構造と中身を表示させる
(8, 8)
[[192 203 199 206 131 200 200 196]
[195 198 46 35 37 48 200 200]
[199 200 25 31 200 142 110 194]
[196 176 30 124 186 194 55 198]
[201 69 87 194 195 171 75 203]
[200 48 107 200 192 58 131 188]
[200 89 31 81 38 49 194 198]
[192 197 141 80 179 194 192 199]]
狙い通り8×8のデータになりましたが、学習データとの違いが2つありました。
- 256階調(学習データは16階調)
- 地が大きい値、数字部分が小さい値(学習データは逆)
ということで、テキストの15章で勉強した通り、配列の演算を用いて変換することにしました。
import numpy as np #NumPyをインポート image=16-np.round(image/16) #画像データを256階調から16階調にし、16から引いて大小の関係を入れ替える print(image) #画像データを表示させる
[[ 4. 3. 4. 3. 8. 4. 4. 4.]
[ 4. 4. 13. 14. 14. 13. 4. 4.]
[ 4. 4. 14. 14. 4. 7. 9. 4.]
[ 4. 5. 14. 8. 4. 4. 13. 4.]
[ 3. 12. 11. 4. 4. 5. 11. 3.]
[ 4. 13. 9. 4. 4. 12. 8. 4.]
[ 4. 10. 14. 11. 14. 13. 4. 4.]
[ 4. 4. 7. 11. 5. 4. 4. 4.]]
構造が揃いました。これでできそうです。
自分の手書き数字を分類する
手書き数字の分類モデルを作る
先ず、テキストで紹介されていた手書き数字の分類器作るプログラムは以下の通りです。
from sklearn import datasets from sklearn import svm, metrics import matplotlib.pyplot as plt # 手書き数字データセットを読み込む digits = datasets.load_digits() X = digits.data # 手書き数字データ y = digits.target # ターゲット n_train = len(X)*2//3 # データの2/3の個数 # 訓練データ X_train, y_train = X[:n_train], y[:n_train] # 前半 2/3 # テストデータ X_test, y_test = X[n_train:], y[n_train:] # 後半 1/3 # 学習器の作成と学習 clf = svm.SVC(gamma=0.001) # 学習器 clf.fit(X_train, y_train) # 訓練データと教師データで学習する
テキストには、できたモデルの評価方法なども書かれていますが、今回は割愛します。
自分の手書き数字を分類する
いよいよ、自分が書いた手書き数字10個を分類してみます。
私が作ったプログラムはこちらです。
os.chdir("/gdrive/My Drive/numbers/") #カレントディレクトリをnumbersに移動 files=os.listdir() #numbersの中身リストをfilesに代入 images=np.zeros((len(files),8,8)) #全ての画像データを入れる配列を作成 data=np.zeros((len(files),64)) #モデルに読み込ませる形にした全てのデータを入れる配列を作成 target=np.zeros(len(files),int) #全ての正解を入れる配列を作成 #画像の読み込み for i,file in enumerate(files): #filesの中から1つずつ番号iと一緒に取り出す images[i]=cv2.imread(file,0) #imagesのi行目に、(i+1)個目の画像データを代入する images[i]=16-images[i]//16 #16階調、地が0になるようにデータを修正 data[i]=images[i].ravel() #imagesのi行目(8×8)を一次元(64×1)にしてdataのi行目に入れる target[i]=int(file.strip("shokutama.jpg")) #ファイル名の数字を正解としてtargetのi行目に入れる #分類する predicted=clf.predict(data) #モデルclfでdataから分類した結果をpredictedに代入する #結果の表示 for index,(image, y_t, ans) in enumerate(zip(images,target,predicted),1): plt.subplot(3,4,index) #3行4列の枡のindex番目に以下の結果を表示する plt.axis("off") #マッピングの軸を表示しない plt.tight_layout() #行間をあける(書かないと上の行のマッピングと下の行のタイトルが被る) plt.imshow(image,cmap="Greys") #index番目の画像データをGreysのカラーマップで表示する plt.title(f"{y_t} pre:{ans}",fontsize=12) #マッピングのタイトルを「(正解),pre:(分類結果)」とする
分類結果
結果は次のようになりました。

正解率:40%
かなり悪いですね。
ちなみに、コントラストがハッキリして比較的キレイなデータができた手書きメモアプリで書いた数字の結果はこちら。

正解率:60%
結構良くなりました。
学習データに私のデータが1つも含まれないので、こんなもんなのかも知れません。
おわりに
「詳細!Python 3 入門ノート」に従って作った手書き数字分類モデルを使って、自分の書いた数字を分類しました。
手書き数字画像の作成から、分類、結果表示まで全てスマホでやることができました。
自分の手書き数字を分類できたことで、Pythonや機械学習を教科書で勉強するだけの机上のものから少し現実世界に近づけたような気分になりました。
できたプログラムコードはこちらす。何かの参考になれば幸いです。
from sklearn import datasets from sklearn import svm, metrics import matplotlib.pyplot as plt # 手書き数字データセットを読み込む digits = datasets.load_digits() X = digits.data y = digits.target n_train = len(X)*2//3 # 訓練データ X_train, y_train = X[:n_train], y[:n_train] # テストデータ X_test, y_test = X[n_train:], y[n_train:] # 学習器の作成と学習 clf = svm.SVC(gamma=0.001) clf.fit(X_train, y_train) os.chdir("/gdrive/My Drive/numbers/") files=os.listdir() images=np.zeros((len(files),8,8)) data=np.zeros((len(files),64)) target=np.zeros(len(files),int) #画像の読み込み for i,file in enumerate(files): images[i]=cv2.imread(file,0) images[i]=16-images[i]//16 data[i]=images[i].ravel() target[i]=int(file.strip("shokutama.jpg")) #分類する predicted=clf.predict(data) #結果の表示 for index,(image, y_t, ans) in enumerate(zip(images,target,predicted),1): plt.subplot(3,4,index) plt.axis("off") plt.tight_layout() plt.imshow(image,cmap="Greys") plt.title(f"{y_t} pre:{ans}",fontsize=12)